来源:新智元(ID:AI_era)
【新智元导读】谷歌Meta之争看来还没完!TensorFlow干不过还有JAX,二番战能否战胜PyTorch?
很喜欢有些网友的一句话:
‘这孩子实在不行,咱再要一个吧。’
谷歌还真这么干了。
养了七年的TensorFlow终于还是被Meta的PyTorch干趴下了,在一定程度上。
谷歌眼见不对,赶紧又要了一个——‘JAX’,一款全新的机器学习框架。
最近超级火爆的DALL·E Mini都知道吧,它的模型就是基于JAX进行编程的,从而充分地利用了谷歌TPU带来的优势。
TensorFlow的黄昏和PyTorch的崛起
2015年,谷歌开发的机器学习框架——TensorFlow问世。
当时,TensorFlow只是Google Brain的一个小项目。
谁也没有想到,刚一问世,TensorFlow就变得非常火爆。
优步、爱彼迎这种大公司在用,NASA这种国家机构也在用。而且还都是用在他们各自最为复杂的项目上。
而截止到2020年11月,TensorFlow的下载次数已经达到了1.6亿次。
不过,谷歌好像并没有十分在乎这么多用户的感受。
奇奇怪怪的界面和频繁的更新都让TensorFlow对用户越来越不友好,并且越来越难以操作。
甚至,就连谷歌内部,也觉得这个框架在走下坡路。
其实谷歌如此频繁的更新也实属无奈,毕竟只有这样才能追得上机器学习领域快速地迭代。
于是,越来越多的人加入了这个项目,导致整个团队慢慢失去了重点。
而原本让TensorFlow成为首选工具的那些闪光点,也被埋没在了茫茫多的要素里,不再受人重视。
这种现象被Insider形容为一种‘猫鼠游戏’。公司就像是一只猫,不断迭代出现的新需求就像是一只只老鼠。猫要时刻保持警惕,随时扑向老鼠。
这种困局对最先打入某一市场的公司来说是避不开的。
举个例子,就搜索引擎来说,谷歌并不是第一家。所以谷歌能够从前辈(AltaVista、Yahoo等等)的失败中总结经验,应用在自身的发展上。
可惜到了TensorFlow这里,谷歌是被困住的那一个。
正是因为上面这些原因,原先给谷歌卖命的开发者,慢慢对老东家失去了信心。
昔日无处不在的TensorFlow渐渐陨落,败给了Meta的后起之秀——PyTorch。
2017年,PyTorch的测试版开源。
2018年,Facebook的人工智能研究实验室发布了PyTorch的完整版本。
值得一提的是,PyTorch和TensorFlow都是基于Python开发的,而Meta则更注重维护开源社区,甚至不惜大量投入资源。
而且,Meta关注到了谷歌的问题所在,认为不能重蹈覆辙。他们专注于一小部分功能,并把这些功能做到最好。
Meta并没有步谷歌的后尘。这款首先在Facebook开发出来的框架,慢慢成为了行业标杆。
一家机器学习初创公司的研究工程师表示,‘我们基本都用PyTorch。它的社群和开源做得是最出色的。不仅有问必答,给的例子也很实用。’
面对这种局面,谷歌的开发者、硬件专家、云提供商,以及任何和谷歌机器学习相关的人员在接受采访时都说了一样的话,他们认为TensorFlow失掉了开发者的心。
经历了一系列的明争暗斗,Meta最终占了上风。
有专家表示,谷歌未来继续引领机器学习的机会正慢慢流失。
PyTorch逐渐成为了寻常开发者和研究人员的首选工具。
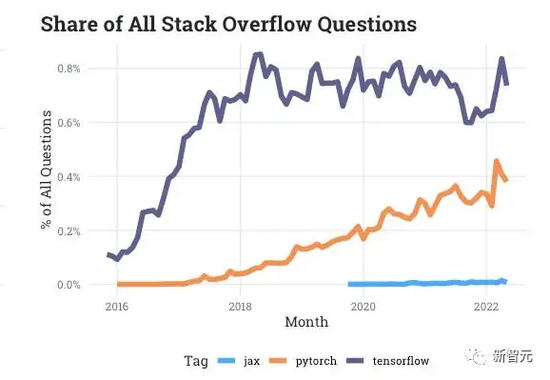
从Stack Overflow提供的互动数据上看,在开发者论坛上有关PyTorch的提问越来越多,而关于TensorFlow的最近几年一直处于停滞状态。
就连文章开始提到的优步等等公司也转向PyTorch了。
甚至,PyTorch后来的每一次更新,都像是在打TensorFlow的脸。
谷歌机器学习的未来——JAX
就在TensorFlow和PyTorch打得热火朝天的时候,谷歌内部的一个‘小型黑马研究团队’开始致力于开发一个全新的框架,可以更加便捷地利用TPU。
2018年,一篇题为《Compiling machine learning programs via high-level tracing》的论文,让JAX项目浮出水面,作者是Roy Frostig、Matthew James Johnson和Chris Leary。
从左至右依次是这三位大神
而后,PyTorch原始作者之一的Adam Paszke,也在2020年初全职加入了JAX团队。
JAX提供了一个更直接的方法用于处理机器学习中最复杂的问题之一:多核处理器调度问题。
根据所应用的情况,JAX会自动地将若干个芯片组合而成一个小团体,而不是让一个去单打独斗。
如此带来的好处就是,让尽可能多的TPU片刻间就能得到响应,从而燃烧我们的‘炼丹小宇宙’。
最终,相比于臃肿的TensorFlow,JAX解决了谷歌内部的一个心头大患:如何快速访问TPU。
下面简单介绍一下构成JAX的Autograd和XLA。
Autograd主要应用于基于梯度的优化,可以自动区分Python和Numpy代码。
它既可以用来处理Python的一个子集,包括循环、递归和闭包,也可以对导数的导数进行求导。
此外,Autograd支持梯度的反向传播,这也就这意味着它可以有效地获取标量值函数相对于数组值参数的梯度,以及前向模式微分,并且两者可以任意组合。
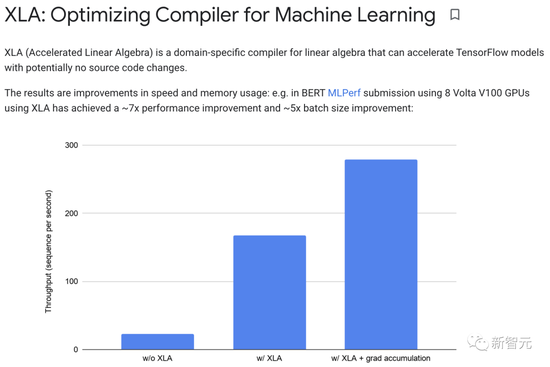
XLA(Accelerated Linear Algebra)可以加速TensorFlow模型而无需更改源代码。
当一个程序运行时,所有的操作都由执行器单独执行。每个操作都有一个预编译的GPU内核实现,执行器会分派到该内核实现。
举个栗子:
def model_fn(x, y, z): return tf.reduce_sum(x + y * z)
在没有XLA的情况下运行,该部分会启动三个内核:一个用于乘法,一个用于加法,一个用于减法。
而XLA可以通过将加法、乘法和减法‘融合’到单个GPU内核中,从而实现优化。
这种融合操作不会将由内存产生的中间值写入y*z内存x+y*z;相反,它将这些中间计算的结果直接‘流式传输’给用户,同时将它们完全保存在GPU中。
在实践中,XLA可以实现约7倍的性能改进和约5倍的batch大小改进。
此外,XLA和Autograd可以任意组合,甚至可以利用pmap方法一次使用多个GPU或TPU内核进行编程。
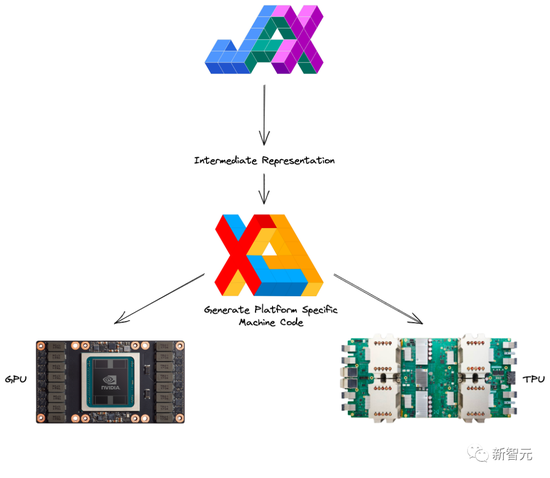
而将JAX与Autograd和Numpy相结合的话,就可以获得一个面向CPU、GPU和TPU的易于编程且高性能的机器学习系统了。
显然,谷歌这一次吸取了教训,除了在自家全面铺开以外,在推进开源生态的建设方面,也是格外地积极。
2020年DeepMind正式投入JAX的怀抱,而这也宣告了谷歌亲自下场,自此之后各种开源的库层出不穷。
纵观整场‘明争暗斗’,贾扬清表示,在批评TensorFlow的进程中,AI系统认为Pythonic的科研就是全部需求。
但一方面纯Python无法实现高效的软硬协同设计,另一方面上层分布式系统依然需要高效的抽象。
而JAX正是在寻找更好的平衡,谷歌这种愿意颠覆自己的pragmatism非常值得学习。
causact R软件包和相关贝叶斯分析教科书的作者表示,自己很高兴看到谷歌从TF过渡到JAX,一个更干净的解决方案。
谷歌的挑战
作为一个新秀,Jax虽然可以借鉴PyTorch和TensorFlow这两位老前辈的优点,但有的时候后发可能也会带来劣势。
首先,JAX还太‘年轻’,作为实验性的框架,远没有达到一个成熟的谷歌产品的标准。
除了各种隐藏的bug以外,JAX在一些问题上仍然要依赖于其他框架。
拿加载和预处理数据来说,就需要用TensorFlow或PyTorch来处理大部分的设置。
显然,这和理想的‘一站式’框架还相去甚远。
其次,JAX主要针对TPU进行了高度的优化,但是到了GPU和CPU上,就要差得多了。
一方面,谷歌在2018年至2021年组织和战略的混乱,导致在对GPU进行支持上的研发的资金不足,以及对相关问题的处理优先级靠后。
与此同时,大概是过于专注于让自家的TPU能在AI加速上分得更多的蛋糕,和英伟达的合作自然十分匮乏,更不用说完善对GPU的支持这种细节问题了。
另一方面,谷歌自己的内部研究,不用想肯定都集中在TPU上,这就导致谷歌失去了对GPU使用的良好反馈回路。
此外,更长的调试时间、并未与Windows兼容、未跟踪副作用的风险等等,都增加了Jax的使用门槛以及友好程度。
现在,PyTorch已经快6岁了,但完全没有TensorFlow当年显现出的颓势。
如此看来,想要后来者居上的话,Jax还有很长一段路要走。
参考资料: https://www.businessinsider.com/facebook-pytorch-beat-google-tensorflow-jax-meta-ai-2022-6
http://finance.sina.com.cn/tech/csj/2022-06-15/doc-imizirau8587764.shtml
| 

 发表于 2022-6-15 20:08:25
发表于 2022-6-15 20:08:25